
技術


こんにちは。シナモンAI 広報担当です。
本日は、シナモンAIベトナム拠点で運営しております、技術ブログの日本語訳版をご紹介したいと思います。本記事の最後にブログへのリンクも掲載しています。是非ご覧ください。
まず始めに、書類について考えてみましょう。事務書類はデータを伝達、保存、検索するためのツールとして重要な役割を果たしています。
現に、そうした事務書類は、医師が患者用の明細を作成する際や、事務員が顧客に請求書を提供する際に発生しており、デジタルデータベースへの保存を行うまでの中間的な手段としても用いられています。
このような事務書類からの情報抽出(IE)は医師、顧客、経理、研究者、営業担当者などといった、さまざまな立場の方にとって日常的に必要なものとなるでしょう。
多岐にわたる利用者が存在するため、私たちは、IEには非常に高レベルの精度が求められるのではないかと考えています。それに加え、抽出された情報の検証に向けた、一定レベルの専門知識が必要になる可能性もあります。
シナモンで構築しているFlax Scannerは、上記のような事務書類から適切な情報を抽出するために設計されています。
Flax Scannerは診療明細書、請求書、保険申込書などを正確かつ効率的な手法で読み取ることができます。
今後の記事で紹介予定のディープラーニングベースのパイプラインを利用して、Flax Scannerでは、アノテーションを施した少量の書類から容易に再トレーニングすることが可能です。
私たちはこのプロダクトの構築を通じて、医師や薬剤師の皆様が学習・研究に費やせる時間を増やしたいと考えています。またバックオフィス担当者の皆様に、デジタルデータの検討や活用に割く時間を増やし、全体の生産性向上を達成していただきたいと願っています。
このブログ記事シリーズでは今後、弊社のFlax Scannerシステムの各コンポーネントを取り上げ、その主な性能のほか、弊社が開発してきた注目の特性である「説明可能性」について検証していきます。
ここまで見てきたように、Flaxの利用者は多岐にわたり、一部のユースケースでは非常に高レベルの精度が求められる可能性があります。
そのため、Flaxには上述のさまざまな書式やレイアウトを処理すると同時に、各書式について高レベルの精度を維持できることが要求されます。
弊社のFlax Scannerシステムの全体は、主に以下の2種類のモジュールから成っています。
ここでは、まず以上のモジュールを取り上げることにします。その他の重要なコンポーネント(Explainer)については、次回以降にご紹介する予定です。
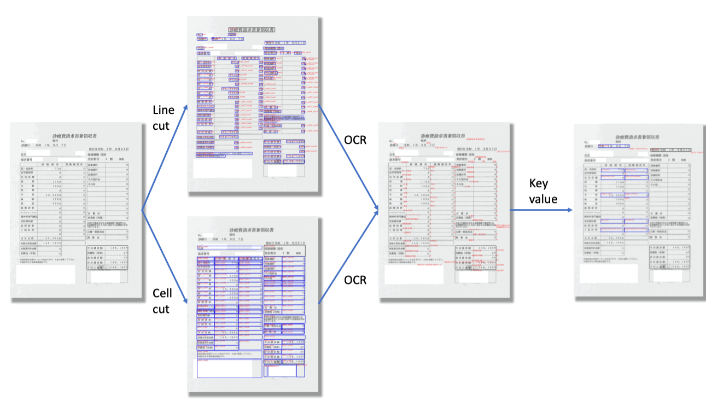
エンジニアや研究者の皆様からは、「情報抽出(IE)の実行前に、まず書類画像を分解する必要があるのはなぜですか?」という質問が多く寄せられます。
確かに、Faster RCNN [2]やYOLO [3]のようなオブジェクト検出技術を全体構造に向けて適用することも魅力的ですが、私たちはそれを採用していません。
私たちはDocument Object Detectionを汎用モジュールにして、あらゆる書類を扱えるようにした方がよいと考えています。その背景には、診療明細書には薬の名前、請求書には商品価格が必要であるなど、それぞれの書類や書式にはそれ特有のフィールドの抽出が求められる、という点があります。
従って、それらすべてをカバーする中間表現が必要になるのです。
「画像の分解」の後は、その先のキー・バリュー(Key-Value)抽出に向け、有用な情報すべてを検出、位置特定、認識することがタスクの目標となります。
弊社のシステムの場合、各オブジェクトの形状と位置はレイアウトサブモジュールが処理し、テキスト行の位置・画像からテキスト内容への変換は光学文字認識(OCRモジュール)が担当します。
すぐ上で述べたように、レイアウトモジュールは表、印影、テキスト行といった、書類の中間的な構成要素の位置を特定するために使われます。このモジュールは画像の入力を受け取り、そうした構成要素の座標と寸法を出力します。
現実のシナリオだと、書類のレイアウトの形状、サイズ、画像の質、照明条件がさまざまであるため、画像を特定の中間形式に正規化するのは困難です。

しかし、私たちは改良を重ね、拡張(Augmentation)手法のほか、さまざまな機能(歪み補正、コントラスト強化、向き補正など)を適用してきました。それを通じて実現したモジュールは、多岐にわたる照明・背景条件の下でも、書類画像内のテキスト領域、印影、表といった主な構成要素の検出について高性能(IoU〔Intersection over Union〕が約0.9)を達成できています。
次に、Layout(レイアウト)モジュールから得られた位置情報を利用して、テキスト行の画像が切り出されます。これによって、OCRモジュールがそれをテキストデータに変換できるようになります。
ここで触れておきたいのは、OCR技術の開発は長い歴史を持っているという点です。研究者らは投影分布や自らの手で作り出した機能を利用して、画像からテキストへの変換を試みてきました。
シナモン AI では、最先端のディープラーニングアーキテクチャを利用して、多岐にわたる条件下での、最大限のパフォーマンスと精度を獲得しています。
上述のような照明、形状、フォントに関する課題はレイアウトとOCRの両方に影響しますが、それだけでなく、OCRが現実世界のユースケースを実際に扱うためには、印刷文字に加え、手書き文字も処理できなければなりません。


ここ何年かの間、AI分野の研究者は特定タスクの解決に向け、人間の脳を模した多種多様なニューラルネットワークアーキテクチャを開発してきました。そのような画像・テキスト情報の処理に向けたネットワークの中でも人気があり、私たちのシステムに利用できるものとして、畳み込みニューラルネットワーク(CNN)と再帰型ニューラルネットワーク(RNN)があります。以下の節では、これらのアーキテクチャについて順番に説明していきます。
Document Object Recognition(DOR)への入力は画像であり、その画像はCNNの利用によって、一連の特徴マップに自動変換されます。畳み込み層を経る中で、視覚的手がかりが各特徴マップに集約され、最終層からはテキスト行の位置を表すマスクが引き出されます。この記事では、書類画像の最も一般的な構成要素であるテキスト行のみを説明対象とします。以上のプロセスはテキスト行のセグメンテーションと呼ばれます。
畳み込みネットワークの具体的なアーキテクチャのうち、セグメンテーションタスクに向けた高度なものとして、AR-UNETがあります。
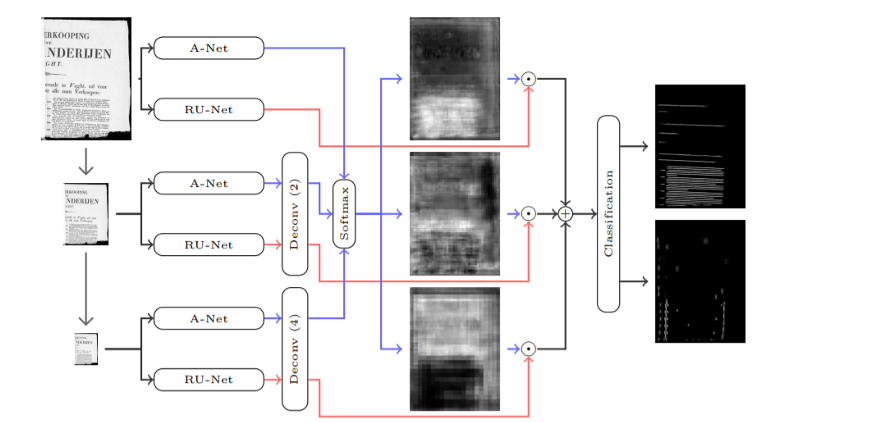
画像に対してセグメンテーション(レイアウト検出)を適用したら、テキストボックスの位置を獲得できると期待してしまいそうですが、ここではまだ特徴マップ(これは多数のイメージとして確認できます)しか得られていません。それをテキスト表現に変換するには、光学文字認識(OCR)プロセスを実行する必要があります。そこで登場するのが、畳み込み再帰型ニューラルネットワーク(CRNN)です。
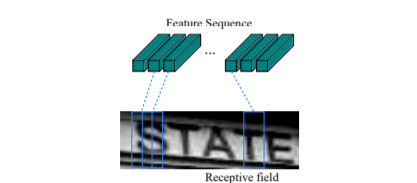
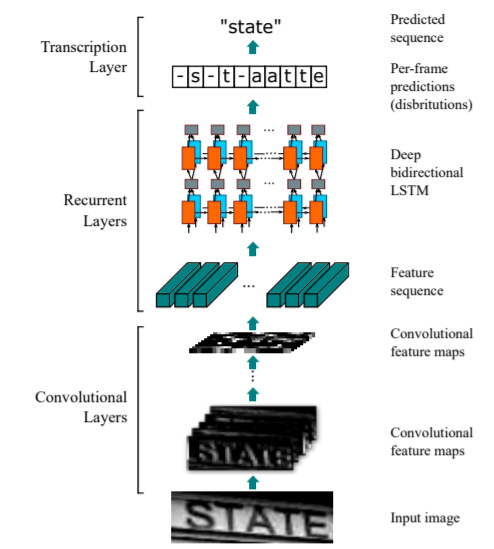
1個の文字を含んでいる可能性のある長方形を、特徴量系列内でスライドさせ、それについて検討を行うことで、RNNはそれらの系列間の関係を順方向・逆方向の両方で学習します。最後に、文字予測はCTC確率モデルに受け渡されます。このモデルは書類画像内に存在する可能性のある文字列すべての信頼度スコアを計算してから、最終的な正しい文字列を決定します。CRNNアーキテクチャのフロー全体は、以下の画像に示されています。
この初回記事では、Flax Scannerの概要をご紹介しました。ソリューションが直面する可能性のある課題についても取り上げ、Document Object Recognitionコンポーネントの課題で用いられている有望な解決策の一部について論じました。その他のコンポーネントや弊社のシステムについてさらに詳しく知りたい方は、次回以降の記事にご期待ください。
[1] Grüning, T., Leifert, G., Strauß, T., Michael, J., & Labahn, R. (2018). A Two-Stage Method for Text Line Detection in Historical Documents. https://doi.org/10.1007/s10032-019-00332-1
[2]Ren, S., He, K., Girshick, R., & Sun, J. (2017). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031
[3] Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2016-Decem, 779–788. https://doi.org/10.1109/CVPR.2016.91
本記事の英語版はこちらよりご覧いただけます。
本記事に関するお問合せや、商談のご希望はこちらからご連絡くださいませ。
また、シナモンAIでは定期的にセミナーを実施しております。
(文責:森田)

