
経営


企業も行政も、これからの時代はAIの活用が避けては通れません。そこで重要なのが、AIモデルにあてはめる学習データを、どのようにストックしておくかということです。
企業には多かれ少なかれ、これまでの事業活動を通して得た多様なデータが蓄積されています。しかし、それらをただ手元で寝かせておくだけでは無意味。AIの活用に備え、半ばデッドストック化しているデータを、“使えるデータ”に替えていく必要があります。
そこで私は先日、「高度情報通信ネットワーク社会推進戦略本部(第78回)官民データ活用推進戦略会議(第9回)合同会議」の席で、「Linking Dataを前提とするデジタル基盤の整備」を提案させていただきました。
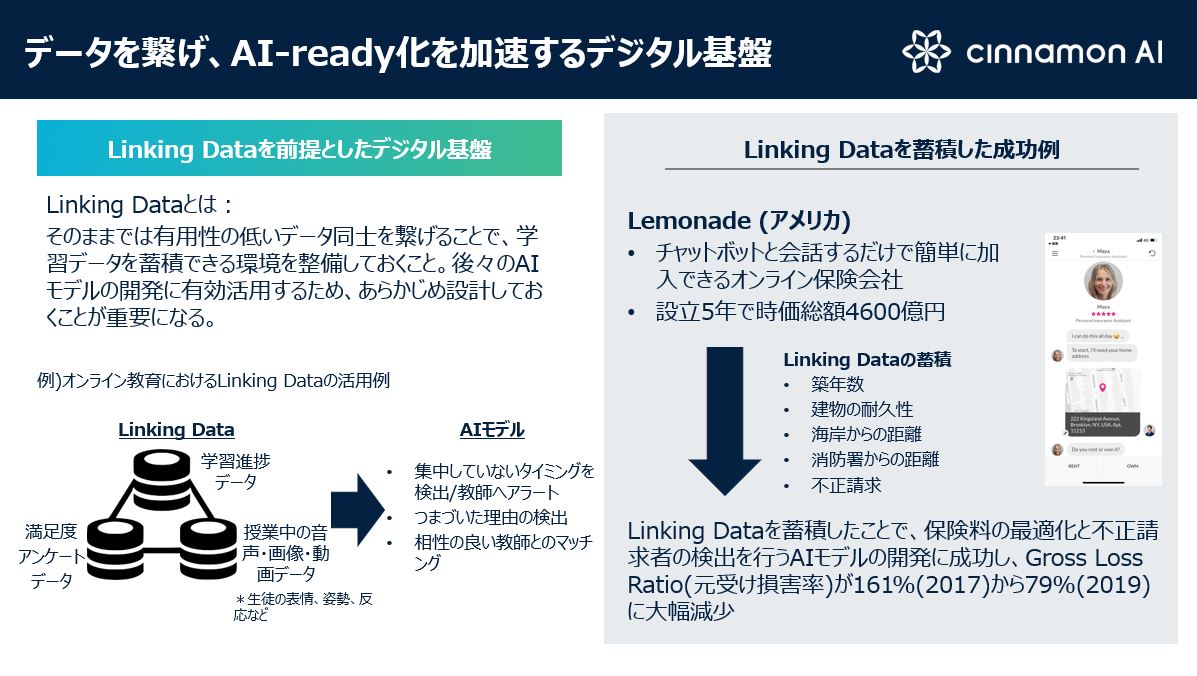
Linking Dataとは、AIモデルの開発のために、既存のデータ同士を繋げた状態を意味します。単体では有用性の低いデータであっても、集積して連携させることで、AIにとって有効な学習データとなり得るのです。
オンライン英会話教室の事業モデルを例に考えてみましょう。レッスン風景の動画や音声をそのまま残しておくだけでは、単なる記録映像にしかなりません。しかし、授業の後に毎回、受講生に対して授業の満足度をアンケート調査し、その結果をレッスン動画と連携させてみるとどうでしょう。受講生の表情やリアクションなどから、AIが満足度の傾向を自動で予測できるようになります。
このようなAIモデルが実現すると、授業を進行する中で受講生の反応をリアルタイムで教師にフィードバックすることが可能になります。すると何が起こるのか――?
「今の内容はあまり理解されていないようだから、もう少し詳しく解説しよう」
「講義が少し単調になってきたようだから、このあたりで違った切り口のレッスンを取り入れてみよう」
「今日の教え方は効果的のようだから、次回以降もこのやり方を踏襲していこう」
このように、AIからのレコメンデーションを受けて、授業のやり方をより良い方向に改善し、生徒の満足度が高められることは、競合事業者に対して大きなアドバンテージとなるはず。つまり、レッスン風景の動画と満足度をLinkingすることで、非常に価値のあるデータが生まれるわけです。
実際にLinking Dataを有効活用している事例を挙げてみましょう。
アメリカのオンライン損害保険会社「Lemonade」では、Mayaと名付けられたAIチャットボットと対話するだけで、ほんの数分で加入手続きを完了できるサービスを展開しています。そして最も注目すべきユーザーエクスペリエンス(以下、UX)は、加入手続きだけでなく、火災などの有事が発生した場合でも、Mayaとのやり取りのみで数分後には保険金が支払われることです。
従来の保険会社であれば、コールセンターへの連絡や必要書類の提出など、煩雑なプロセスをいくつも経た上でようやく数カ月後に保険金が支払われるのが一般的。この圧倒的なUXにより、Lemonadeは設立5年で上場を果たし、時価総額は早くも約4600億円に達する急成長を遂げたのです。
Lemonadeの保険の損害率(※収入保険料に対する支払保険金の割合)を見ても、事業モデルの優位性は明らかです。
2017年の損害率は161%で、すなわち加入者から10万円の保険料が支払われたのに対し、Lemonadeは16万1000円の保険金を支払っていることを示します。この段階ではまだ、加入者が増えれば増えるほど損益が拡大し、経営的にはまさに火の車状態であったわけです。
ところが、翌2018年になると損害率は113%に、さらに昨年には79%に転じます。つまりこの2年で急速な黒字化が進んだわけで、Lemonadeの事業モデルが完成に至ったことを意味しています。
では、Lemonadeはどうやって僅か2年で161%から79%という、大幅な損害率の圧縮に成功したのでしょうか? 答えは簡単。Lemonadeは加入者数を増やす一方で、データの蓄積に余念がなかったのです。
該当する建物の築年数、耐久性、消防署からの距離……etc。リスクに関わるあらゆるデータの収集に努め、どのような物件が保険料の支払いが多く、逆にどのような物件であれば支払いが抑えられるのかをAIで分析し、加入者ごとに保険料をパーソナライズしたのです。ここで活用されたのがまさに、Linking Dataです。
今のところ、このレベルでAIを活用している事業者は、日本の損害保険業界には見当たりません。しかし本来、災害大国と言われる日本こそ、Lemonadeの事例に習うことは多いはずなのです。
心当たりのある人も多いと思いますが、このコロナ禍で急速に会議利用が進んだメッセンジャーツールの中には、終了と同時に満足度を問うアンケートが表示されるものがあります。
クリアな通話が維持されていたか。ノイズに邪魔をされることはなかったか。インターフェースの利便性をどう感じたか。これもまた、ユーザーそれぞれの評価を収集することでLinking Dataを作成している身近な事例です。そして、AI活用に長けた企業はすでに日常的にデータ収集を行なっているという好例でしょう。
繰り返しになりますが、大切なのは今あるデータをLinking Data化して備えておくことです。もし活用可能なデータが見当たらないのであれば、重要な数値や指標の収集を始めることが第一であり、いずれも今すぐに着手できる作業であるはず。「AIなんてまだまだ先のこと……」とぼんやりしていては、いざその時がやって来た時に、活用すべき学習データが手元にまったくない、という事態になりかねません。
とりわけ「2030年問題」と言われる団塊の世代の一斉リタイアが迫っている昨今、ナレッジマネジメントの一環としてもLinking Dataは重要な意味を持っています。
日本の経済成長を支えてきた製造業の現場でも、これまでの資料や報告書の類いが有効活用されているケースは少なく、有用性の高い知識やノウハウが去りゆく人材の頭の中にしか残っていないという話をよく耳にします。このまま2030年代を迎えてしまうと、日本の産業は大きな損失を被り、危機的な状況に陥るといっても過言ではないでしょう。
つまりLinking Dataの整備は、ナレッジを継承する手間や時間を大幅に削減することにも繋がります。何らかのトラブルが発生した際に、過去の事例や先達のノウハウに習おうとしても、それがLinking Dataとしてまとめられていなければ、スピーディーな対応はとても望めません。
また、こうして皆さんが日常的にアクセスしているウェブメディアにしても、1コンテンツあたりのテキスト量や画像点数、内容などから、読者の離脱率を測定している事業者が少なくありません。現状は、より読まれるコンテンツを作るための参考データにとどまっていても、これを一歩進めれば、AIによって自動的にヒット記事が作れるようになるでしょう。
たとえばオーサーがブログを執筆している最中に、離脱率を下げるためにAIが「そろそろ小見出しを挿入しましょう」、「文字量が多いので注意してください」などと助言してくれるような時代も、さほど遠い未来の話ではないのです。
まずは身の回りにどのようなデータが存在するのか、あらためて見直してみるところから始めてることがお勧めです。
 シナモンAI 代表取締役社長CEO 平野未来シリアル・アントレプレナー。東京大学大学院修了。レコメンデーションエンジン、複雑ネットワーク、クラスタリング等の研究に従事。2005年、2006年にはIPA未踏ソフトウェア創造事業に2度採択された。在学中にネイキッドテクノロジーを創業。IOS/ANDROID/ガラケーでアプリを開発できるミドルウェアを開発・運営。2011年に同社をミクシィに売却。ST.GALLEN SYMPOSIUM LEADERS OF TOMORROW、FORBES JAPAN「起業家ランキング2020」BEST10、ウーマン・オブ・ザ・イヤー2019 イノベーティブ起業家賞、VEUVE CLICQUOT BUSINESS WOMAN AWARD 2019 NEW GENERATION AWARDなど、国内外の様々な賞を受賞。また、AWS SUMMIT 2019 基調講演、ミルケン・インスティテュートジャパン・シンポジウム、第45回日本・ASEAN経営者会議、ブルームバーグTHE YEAR AHEAD サミット2019などへ登壇。2020年より内閣官房IT戦略室本部員および内閣府税制調査会特別委員に就任。プライベートでは2児の母。 シナモンAI 代表取締役社長CEO 平野未来シリアル・アントレプレナー。東京大学大学院修了。レコメンデーションエンジン、複雑ネットワーク、クラスタリング等の研究に従事。2005年、2006年にはIPA未踏ソフトウェア創造事業に2度採択された。在学中にネイキッドテクノロジーを創業。IOS/ANDROID/ガラケーでアプリを開発できるミドルウェアを開発・運営。2011年に同社をミクシィに売却。ST.GALLEN SYMPOSIUM LEADERS OF TOMORROW、FORBES JAPAN「起業家ランキング2020」BEST10、ウーマン・オブ・ザ・イヤー2019 イノベーティブ起業家賞、VEUVE CLICQUOT BUSINESS WOMAN AWARD 2019 NEW GENERATION AWARDなど、国内外の様々な賞を受賞。また、AWS SUMMIT 2019 基調講演、ミルケン・インスティテュートジャパン・シンポジウム、第45回日本・ASEAN経営者会議、ブルームバーグTHE YEAR AHEAD サミット2019などへ登壇。2020年より内閣官房IT戦略室本部員および内閣府税制調査会特別委員に就任。プライベートでは2児の母。 |
シナモンAIでは、コンサルティング、ワークショップ、ソリューションの提供を通じて、「AIを競争戦略に結びつける」お手伝いをさせていただいております。ぜひお気軽にお声がけをいただけましたら幸いです。
お問い合わせはこちら => お問い合わせフォーム
